Introduction
Overview
Kafka is an open-source stream-processing software platform developed by the Apache Software Foundation and written in Scala and Java. It is designed to be horizontally scalable, fault-tolerant, and to provide both a publish–subscribe and a storage and processing system. It is used for building real-time data pipelines and streaming apps. Popular use cases include streaming analytics, IoT and messaging.
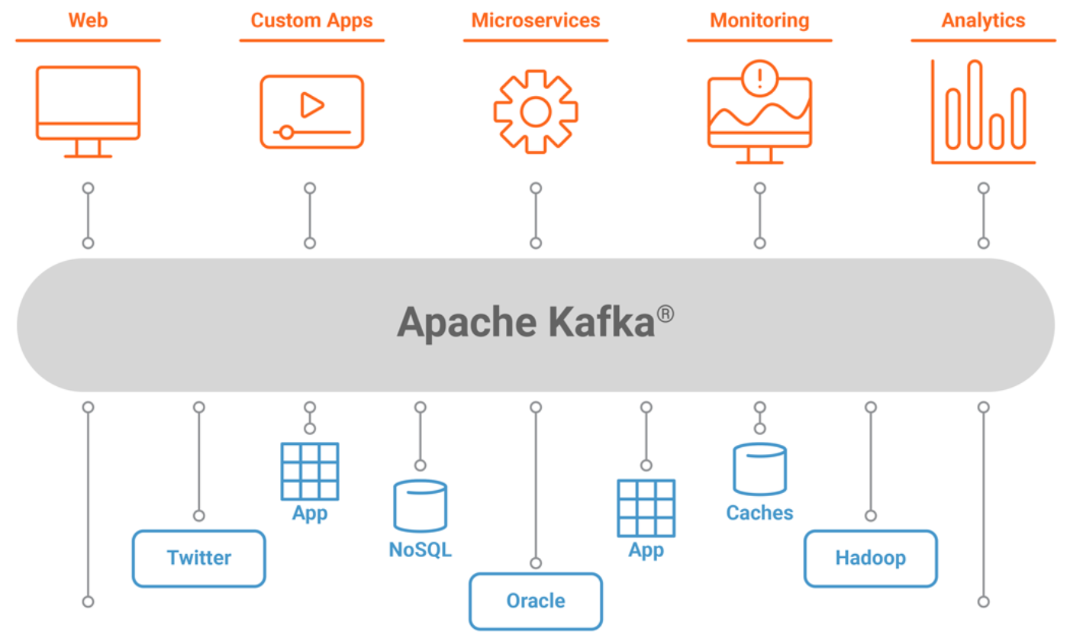
Kafka Use Cases
- Messages
- Website Activity Tracking
- Metrics
- Log Aggregation
- Stream Processing
- Event Sourcing
- Commit Log
Description of use cases
Messaging
- Kafka works well as a replacement for a more traditional message broker. Message brokers are used for a variety of reasons (to decouple processing from data producers, to buffer unprocessed messages, etc). In comparison to most messaging systems, Kafka has better throughput, built-in partitioning, replication, and fault tolerance which makes it a good solution for large-scale message processing applications.
Website Activity Tracking
- The original use case for Kafka was to be able to rebuild a user activity tracking pipeline as a set of real-time publish-subscribe feeds. This means site activity (page views, searches, or other actions users may take) is published to central topics with one topic per activity type. These feeds are available for subscription for a range of use cases including real-time processing, real-time monitoring and loading into Hadoop or offline data warehousing systems for offline processing and reporting.
Metrics
- Kafka is often used for operational monitoring data. This involves aggregating statistics from distributed applications to produce centralized feeds of operational data.